Today I opened Hugging Face to check what was new since my last visit. Yesterday on the Blog section I found this interesting post which I highly recommend you to read: https://huggingface.co/blog/allenai/olmoearth-v1-1
But today I discovered a new section which is really cool: Languages (https://huggingface.co/languages). It is basically listing all languages covered by Hugging Face through both models and datasets. You can see how many models and datasets exist for a given language. This is very useful to see which languages have a high coverage and identify which ones are low-resource languages (and therefore are a very interesting starting point to help the field progress).
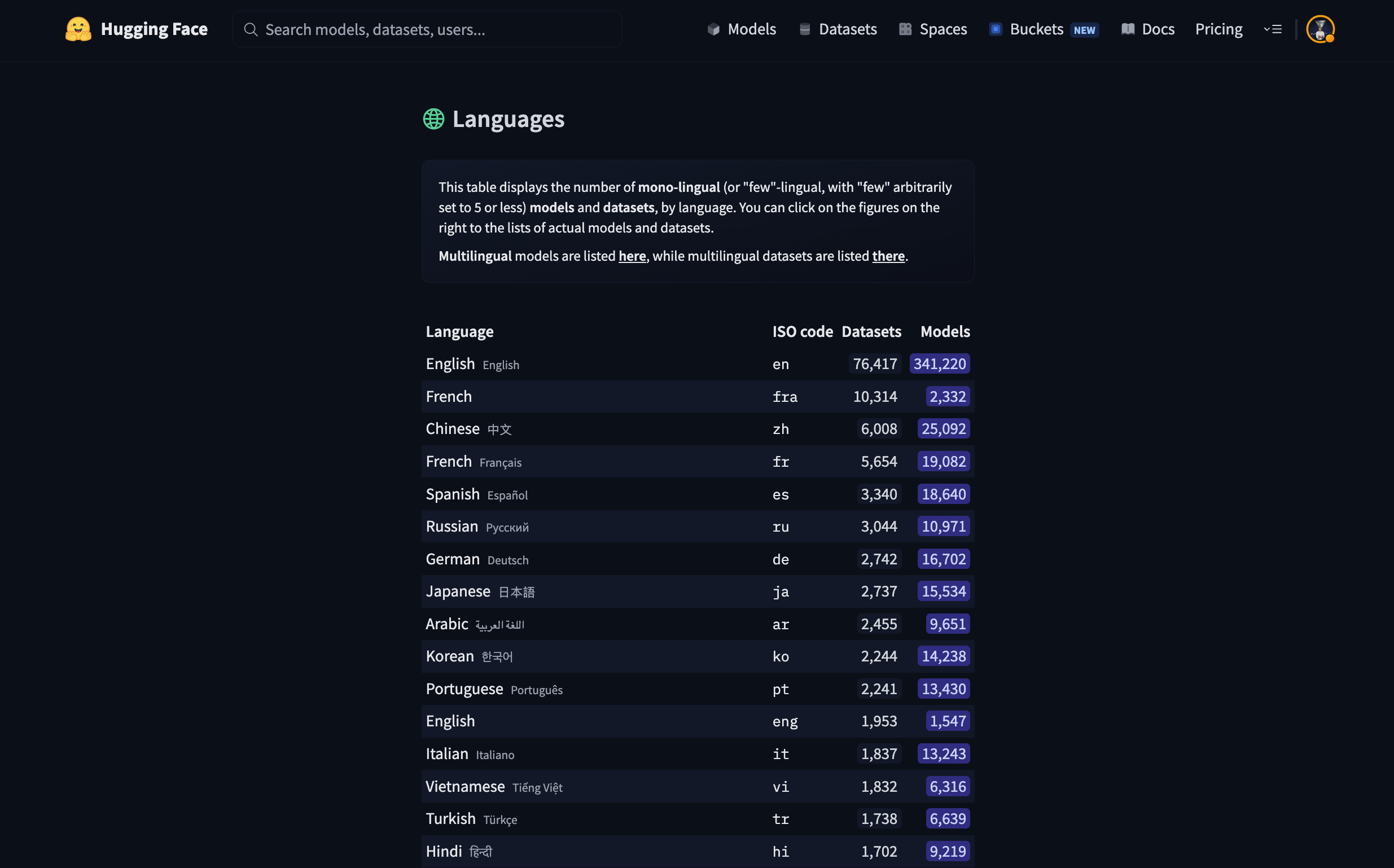
The Hugging Face Languages page lists model and dataset counts for each language.
While scrolling down to the low-resource languages, I found one pathological case which caught my attention. It is Enawené-Nawé which is an indigenous language from Brazil. What looks uncommon with this line is that it has a very low number of datasets, 4 in this case, but abnormally it has 808 models. When looking at its neighbors, it does look like an outlier.
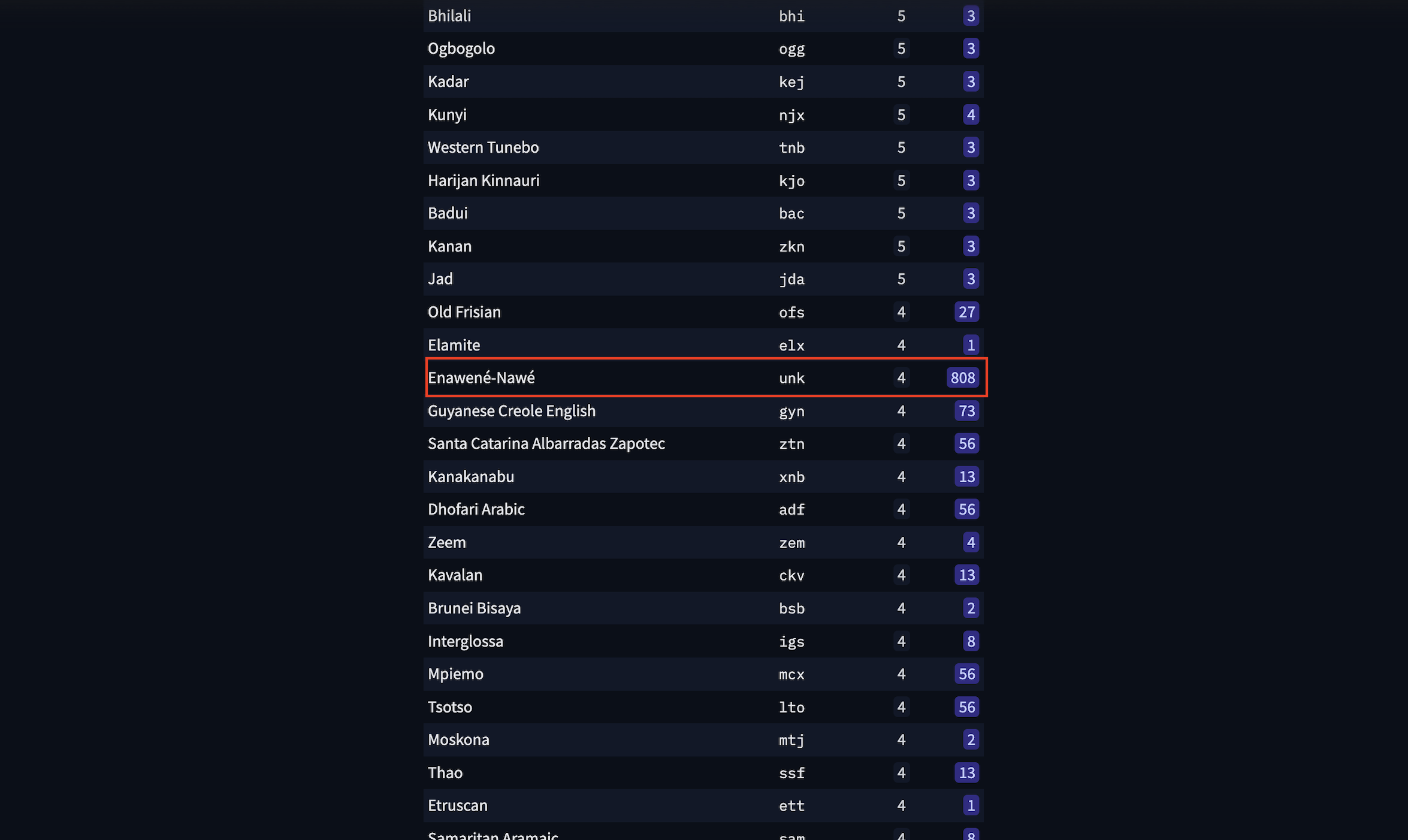
The Enawené-Nawé row stands out with 4 datasets but 808 models.
When you filter models by this language you get the following list, which at first glance does not seem like they are about this language whatsoever.
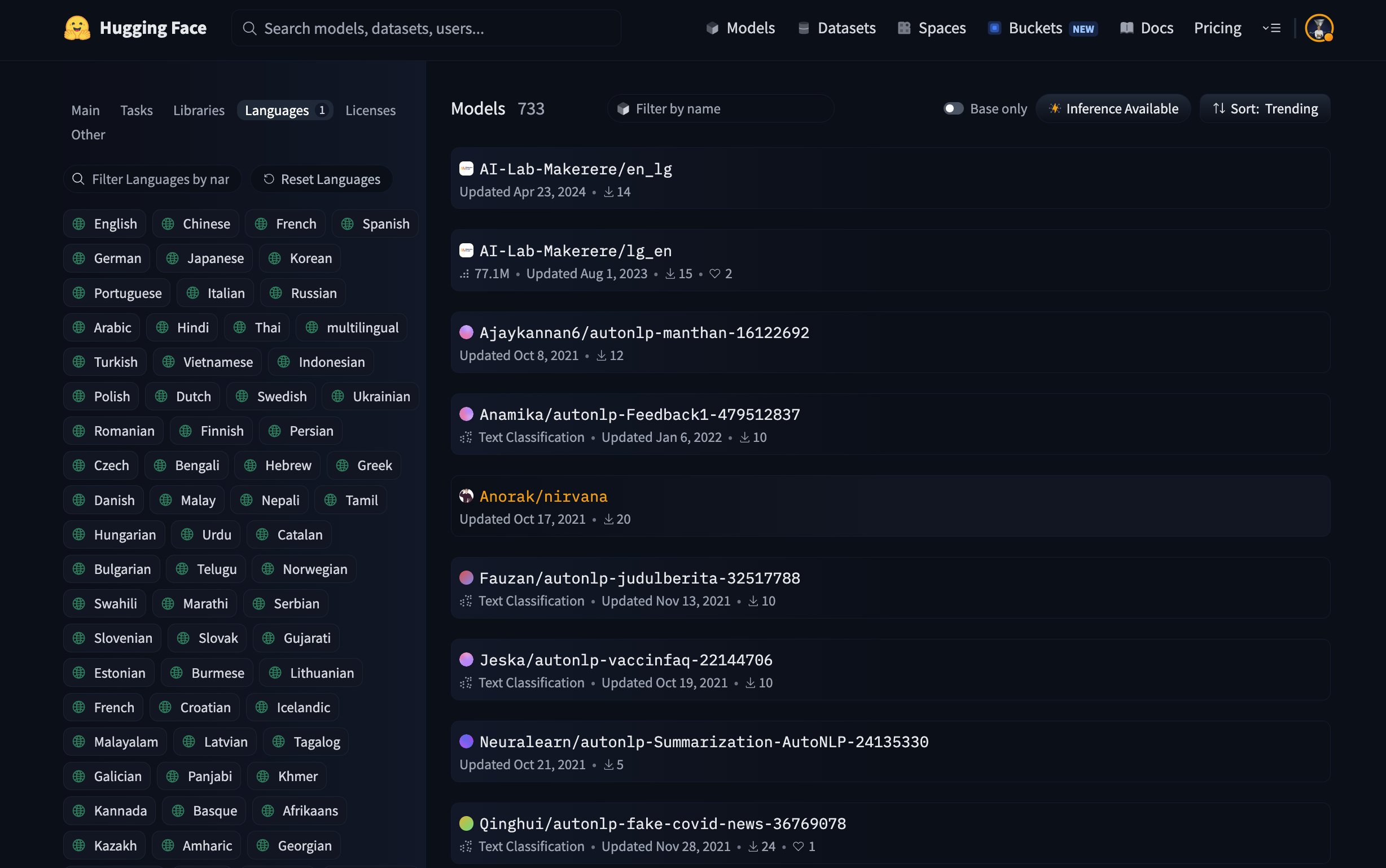
The model list returned by the Enawené-Nawé language filter does not appear to be about Enawené-Nawé.
In fact I opened a few of them and the pattern is very similar. Almost all of them are models created by using AutoNLP, which is a Hugging Face low/no-code tool to help you train a model on your dataset. However, as you can see by the model names, these models are not covering Enawené-Nawé. The first model for example rather looks like a translator English <=> Luganda. When you look at the ISO code of this language, you will find out that it is “unk”. One hypothesis could therefore be that these models used this “unk” tag for the language as a way to flag the model language as “unknown”. However it is attributed to this indigenous language incorrectly and therefore is misleading on its actual coverage.
Beyond this example which is maybe just a corner case, this raises the question of the reliability of this tag method. Users are free to use any tag they want while publishing a dataset, which can, by several means, inflate stats for some languages:
- We can mistakenly tag a language which is not covered (or omit one)
- A malicious actor could publish many datasets with tagged languages that were never covered
- With the usage of coding agents becoming increasingly popular, dataset cards writing can often be handed to the agent, which might hallucinate some tags
While useful, language tags on Hugging Face should not be taken at face value for the reasons mentioned above, and should always require a deeper investigation. Furthermore, even in the case of a correct count, this remains a proxy metric which does not account for the content and quality of models and datasets.